Create Table
之前跟 DynamoDB 不是很熟, 在Create Table的設計上,先後換了好幾個版本.
最後版本是這樣子的:
Table name: ip_geo_table
Primary key :
partition key: partition (string)
sort key: num_start (number)
Provisioned capacity:
Read capacity units: 1
Write capacity units: 1 (匯入資料前,拉高至100,理由後述)
Secondary indexes:
不需建任何二級索引
Primary Key 規劃
DynamoDB 支援兩種類型的Primary Key:
- Partition Key : 例如 身分證字號、流水號
- Partition Key + Sort Key : 例如 星座+身分證字號
不論哪種類型, Primary Key 都要具有唯一性.
以前看Best Practice 的文件,總是說要慎選 Partition Key, 分組做得不好,將會影響查詢效能等等。 文件是這麼說的:
| Partition key | 均勻性 |
|---|---|
| 用戶 ID,應用程序中有許多用戶 | 好 |
| 狀態代碼,只有幾個可用的狀態代碼 | 差 |
| 項目創建日期,四捨五入至最近的時間段(例如天、小時,分鐘) | 差 |
| 設備 ID,每個設備以相對類似的間隔訪問數據 | 好 |
| 設備 ID,被跟踪的設備有很多,但到現在為止,其中某個設備比其他所有設備更加常用。 | 差 |
所以第一代Table的設計是這樣子的:
Partition Key : IP的第一組數字, 例如168.95.1.1 => 168
Sort Key : IPv4 區段第一個IP 轉換的 int 數字
甚至自作聰明, 使用另一種Hash的版本
Partition Key : IP的第一組數字再Hash, 例如168.95.1.1 => 168 => 84547012_168
Sort Key : IPv4 區段第一個IP 轉換的 int 數字
後來發現 AWS 官方討論區裡有客服出來說明不需要這麼做, DynamoDB內部機制會處理掉,才知道這是多此一舉的行為.
DynamoDB will take the value you supply and hash it internally.
Therefore, you do not need to worry about consecutive numbers or keys with a similar prefix.
至於最後的版本是
Partition Key : 'ipv4' 字串
Sort Key : IPv4 區段第一個IP 轉換的 int 數字
這個純粹是好奇心驅使, 這樣做其實依舊保持唯一性, 那到底會不會拖慢效能? 這個資料庫一共有 24萬筆左右的資料. 算是不大也不小的規模, 但是結果令人驚喜:一樣快.
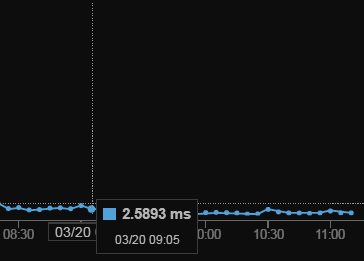
亂數IP測試查詢, 平均只有 2~3 ms ,也就是 0.002~0.003 秒, 非常快. 這或許資料是太少了, 以後應該找時間測試一下百萬、千萬筆規模的資料. 至於現階段這樣子已經很令人滿意, 既然效能一樣快,那設計上簡單就好.
匯入資料
24萬筆的資料數量不少, 匯入到 DynamoDB時, 環境的配置也須注意:
- 開一台 EC2 (t2.nano可) , 把程式丟上去跑, 效率比在你的local端好很多.
- 匯入前, 將DynamoDB 的寫入吞吐量改到 100 以上.
- 匯入完畢後, 記得再改回來.
寫入吞吐量 100的意思就是: 效能提高到每秒可寫入 100筆(小資料)的程度. 計費時間是1個小時(不足一個小時的話以一個小時計, 跟EC2的概念相似).
我們有24萬筆資料要寫, 估計的時間為:
24萬筆/ 每秒100筆/60秒 = 40分鐘
Python 匯入範例如下:
import boto3
# GLOBAL VAR
DYNAMODB = boto3.resource('dynamodb', region_name='us-west-2')
DYNAMODB_TABLE = DYNAMODB.Table('ip_geo_table')
def dynamodb_batch_writer(s_content):
'''
批次寫入
partition: 'ipv4'
num_start: 區間第一個ip轉成數字
num_end: 區間最後一個ip轉成數字
country: 國家名稱
country_isocode: 國家iso代碼
cidr:
'''
# 切行
lst_content = s_content.split('\n')
# 寫入
with DYNAMODB_TABLE.batch_writer() as batch:
for item in lst_content:
# 切欄位
lst_col = item.split(',')
# 批次寫入
batch.put_item(
Item={
'partition': lst_col[0],
'num_start': int(lst_col[1]),
'num_end': int(lst_col[2]),
'country': lst_col[3],
'country_isocode': lst_col[4],
'cidr': lst_col[5]
}
)
return None